Algorithm Auditing: Fairness Measures Selection
Source:R/fairness_selection.R
fairness_selection.RdThis function aims to provide a fairness measure tailored to a
specific context and dataset by answering the questions in the developed
decision-making workflow. The questions within the decision-making workflow
are based on observable data characteristics, the properties of fairness
measures and the information required for their calculation. However, these
questions are posed to the user in an easily understandable manner, requiring
no statistical background or in-depth knowledge of the fairness measures.
Obtainable fairness measures include Disparate Impact, Equalized Odds,
Predictive Rate Parity, Equal Opportunity, Specificity Parity, Negative
Predictive Rate Parity, Accuracy Parity, False Positive Rate Parity and False
Negative Rate Parity. The function returns an object of class
jfaFairnessSelection that can be used with associated print()
and plot() methods.
fairness_selection(
q1 = NULL,
q2 = NULL,
q3 = NULL,
q4 = NULL
)Arguments
- q1
a character indicating the answer to the first question of the decision-making workflow ('Is the information on the true values of the classification relevant in your context?'). If
NULL(the default) the user is presented with the first question of the decision-making corresponding to their desired answer. Possible options areNULL(default),1(to indicate 'Yes'), or2(to indicate 'No').- q2
a character indicating the answer to the second question of the decision-making workflow ('In what type of classification are you interested?'). If
NULL(the default) the user is presented with the second question of the decision-making workflow and can respond interactively by selecting the numerical value corresponding to their desired answer. Possible options areNULL(default),1(to indicate 'Correct classification'),2(to indicate 'Incorrect classification'), or3(to indicate 'Correct and incorrect classification').- q3
a character indicating the answer to the third question of the decision-making workflow ('What is more important: a correct classification of the positive class, a correct classification of the negative class, or both?'). If
NULL(the default) the user is presented with the third question of the decision-making workflow and can respond interactively by selecting the numerical value corresponding to their desired answer. Possible options areNULL(default),1(to indicate 'Correct classificvation of the positive class'),2(to indicate 'Correct classificvation of the negative class') or3(to indicate 'Both a correct classification of the positive and of the negative class').- q4
a character indicating the answer to the fourth question of the decision-making workflow ('What are the errors with the highest cost?'). If
NULL(the default) the user is presented with the fourth question of the decision-making workflow and can respond interactively by selecting the numerical value corresponding to their desired answer. Possible options areNULL(default),1(to indicate 'False Positive') or2(to indicate 'False Negative').
Value
An object of class jfaFairnessSelection containing:
- measure
The abbreviation for the selected fairness measure's name.
- name
The name of the selected fairness measure.
Details
Several fairness measures can be used to assess the fairness of AI-predicted classifications. These include:
Disparate Impact. See Friedler et al. (2019), Feldman et al. (2015), Castelnovo et al. (2022) for a more detailed explanation of this measure.
Equalized Odds. See Hardt et al. (2016), Verma et al. (2018) and Picogna et al. (2025) for a more detailed explanation of this measure.
False Positive Rate Parity. See Castelnovo et al. (2022) (under the name Predictive Equality), Verma et al. (2018) and Picogna et al. (2025) for a more detailed explanation of this measure.
False Negative Rate Parity. See Castelnovo et al. (2022) (under the name Equality of Opportunity), Verma et al. (2018) and and Picogna et al. (2025) for a more detailed explanation of this measure.
Predictive Rate Parity. See Castelnovo et al. (2022) (under the name Predictive Parity) and Picogna et al. (2025) for a more detailed explanation of this measure.
Equal Opportunity. See Hardt et al. (2016), Friedler et al. (2019), Verma et al. (2018) and Picogna et al. (2025) for a more detailed explanation of this measure.
Specificity Parity. See Friedler et al. (2019), Verma et al. (2018) and Picogna et al. (2025) for a more detailed explanation of this measure.
Negative Predictive Value Parity. See Verma et al. (2018) and Picogna et al. (2025) for a more detailed explanation of this measure.
Accuracy Parity. See Friedler et al. (2019) and Picogna et al. (2025) for a more detailed explanation of this measure.
The fairness decision-making workflow below aids in choosing which fairness measure is appropriate for the situation at hand (Picogna et al., 2025).
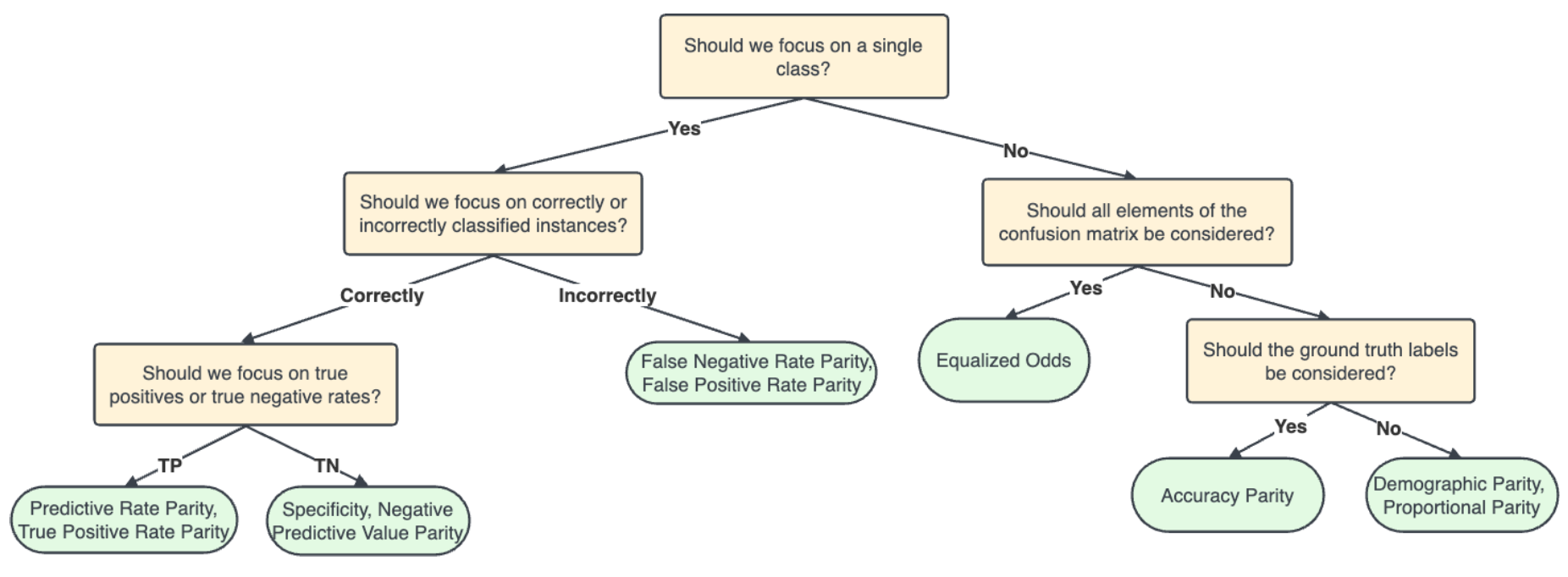
References
Castelnovo, A., Crupi, R., Greco, G. et al. (2022). A clarification of the nuances in the fairness metrics landscape. In Sci Rep 12, 4209. doi:10.1038/s41598-022-07939-1
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. doi:10.1145/2783258.2783311
Friedler, S. A., Scheidegger, C., Venkatasubramanian, S., Choudhary, S., Hamilton, E. P., & Roth, D. (2019). A comparative study of fairness-enhancing interventions in machine learning. In Proceedings of the Conference on Fairness, Accountability, and Transparency. doi:10.1145/3287560.3287589
Hardt M. , Price E., Srebro N. (2016). Equality of opportunity in supervised learning. In Advances in neural information processing systems, 29. doi:10.48550/arXiv.1610.02413
Picogna, F., de Swart, J., Kaya, H., & Wetzels, R. (2025). How to choose a fairness measure: A decision-making workflow for auditors. doi:10.31219/osf.io/cpxmf_v1
Verma S., Rubin J. (2018). Fairness definitions explained. In Proceedings of the international workshop on software fairness, 1–7. doi:10.1145/3194770.3194776
Examples
# Workflow leading to predictive rate parity
fairness_selection(q1 = 1, q2 = 1, q3 = 1, q4 = 1)
#>
#> Fairness Measure for Model Evaluation
#>
#> Selected fairness measure: Predictive Rate Parity
#>
#> Based on:
#> Answer to question 1 (q1): Yes (1)
#> Answer to question 2 (q2): Correct classification (1)
#> Answer to question 3 (q3): Correct classification of the positive class (1)
#> Answer to question 4 (q4): False Positive (1)